随着视频内容越来越多,通过深度模型理解视频,提取视频内容特征,建立视频搜索引擎,已经成为主流。视频内容相似度检索以及视频内容理解能力越发重要。再业务推进过程以及技术积累过程中,对调研尝试过的数据和方法,做简要的整理和剖析。北大满哥视频侵权,说明平台在视频内容审核这一块,严格意义上讲,就平台再视频版权这一块,或多或少的都需要人工运维去做支撑(依据没有运用OCR以及语义等初级的文案审核能力对头部流量视频做内容风控)。显然目前互联网企业的初衷,还在我们的"菜篮子"里,未将精力投入的科技的星辰大海,个人观点。 ## 视频相似问题
处理问题规模
常见的算法都需要的对每帧图片内容做编码,单帧(或者视频段)处理速度,对最终的推理耗时影响很大;比如,单帧耗时指视频流拉取至内存以及单帧图片特征提取耗时(视频读取平均一帧,20ms); (视频)20000 * 帧数(2*60*25)* 单帧耗时50ms/1000/60/60 ~= 833小时;
常见的视频相似度问题
码率变化,格式变化,添加透明水印(少量),分辨率变化,添加文本,裁剪,明显水印,边界扩充;视频内容存在交集,裁剪,边界扩充问题示例。
这里容易出现起义的问题就是,视频段存在交集(episode 内容copy);视频内容存在交集(episode 内容趋同,同样的交互内容);比如最近北大满哥视频抄袭事件,是需要更复杂的语义理解能力,比如语音识别能力,对抄袭文案进行,识别。然当前所有平台再视频版权这一块,或多或少的都需要人工运维去做支撑。如前面所说,目前的互联网企业,还是觊觎我们的"菜篮子",未将精力投入的科技的星辰大海。
数据集
开源数据集
视频+文本
- Microsoft Research Video Description Corpus (MSVD):也称为YouTube2Text dataset,该数据集同样由Microsoft Research提供,地址为 Microsoft Research Video Description Corpus 。该数据集包含1970段YouTube视频片段(时长在10-25s之间),每段视频被标注了大概40条英文句子。
- MSR-VTT (Microsoft Research Video to Text):该数据集为ACM Multimedia 2016 的 Microsoft Research - Video to Text (MSR-VTT) Challenge。地址为 Microsoft Multimedia Challenge 。该数据集包含10000个视频片段(video clip),被分为训练,验证和测试集三部分。每个视频片段都被标注了大概20条英文句子。此外,MSR-VTT还提供了每个视频的类别信息(共计20类),这个类别信息算是先验的,在测试集中也是已知的。同时,视频都是包含音频信息的。该数据库共计使用了四种机器翻译的评价指标,分别为:METEOR, BLEU@1-4,ROUGE-L,CIDEr。
- LSMDC (Large Scale Movie Description Challenge): This dataset contains 118,081 short video clips extracted from 202 movies. Each video has a caption, either extracted from the movie script or from transcribed DVS (descriptive video services) for the visually impaired. The validation set contains 7408 clips and evaluation is performed on a test set of 1000 videos from movies disjoint from the training and val sets.
视频
- CC_WEB_VIDEO - Near-Duplicate Video Retrieval
- FIVR-5K, FIVR-200K - Fine-grained Incident Video Retrieval
- EVVE - Event-based Video Retrieval
- ActivityNet - Action Video Retrieval
竞赛视频数据
- QQ Browser 2021 Ai Algorithm Competition
- 也可以在这里下载:https://share.weiyun.com/S7YSt5sp 密码:78u5bw
开放生产数据
- VCSL 数据集和评测以及算法代码
- https://github.com/alipay/VCSL
业界方案
抖音视频检索能力
- https://www.volcengine.com/product/videohighlights 开放能力:通过多模态AI算法提取精彩片段并剪除重复内容,将其浓缩为精华摘要短视频,应用于广告投放、游戏投放、教育等场景。 分析:多模态算法只用于视频片段内去重,不支持大量视频的检索;
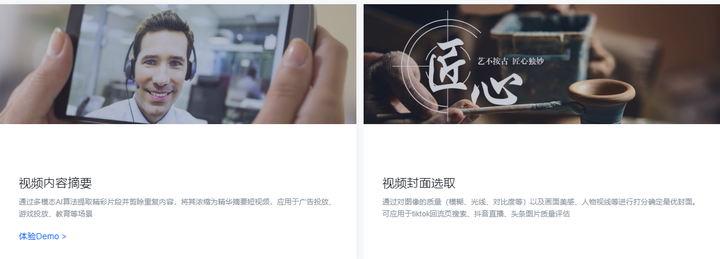
编辑
Image
百度视频检索能力
- https://cloud.baidu.com/doc/MMS/s/Gkbhphdtw
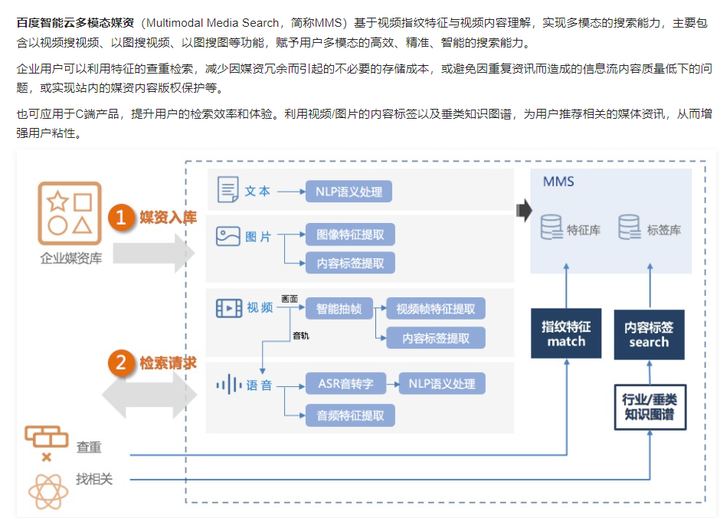
编辑
Image
阿里云开放视频检索能力
- https://retina.aliyun.com/?spm=5176.11914242.J_5253785160.4.57354b57sY8Oed#/DNA/sport
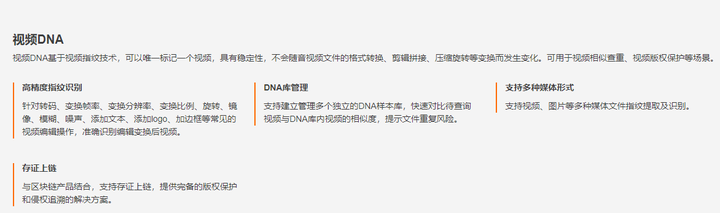
编辑
Image
算法方案
基于视频编码的
- https://github.com/MKLab-ITI/visil
- Video Similarity and Alignment Learning on Partial Video Copy Detection
- https://arxiv.org/pdf/2108.01817v1.pdf
- https://pvcd-vsal.github.io/vsal//results/
基于视频画面-文本联合编码
- https://github.com/willard-yuan/video-text-retrieval-papers
基于视频画面-语音联合编码
- 待补充完善
开源方案
https://milvus.io/cn/docs/v2.0.0/video_similarity_search.md
常用算法
一般提取视频特征分成两步:
- 帧级特征提取,视频画面,或者音频片段特征提取;
- 再获取帧级特征表示后,需要一个时间对齐模,揭示潜在复制视频对之间一个或多个复制片段的相似性和时间范围;
帧级特征获取
从第一步来看,视频检索本质上是对重复画面或者语音片段等的检索识别,从对底层的特征编码能力角度,常见视频相似度查找算法如下;
| 视频相似度度量方案 | 方法分类 | 特点 |
|---|---|---|
| MD5,SHA-256 | 哈希算法 | 只能分析完全相同内容 |
| dHash/aHash/pHash, PDQ | 传统图像感知方案 | 对裁剪、翻转等具有一定的鲁棒性 |
| 深度hash 方案 | 深度hash感知 | 对裁剪、翻转,灰度化等都具有较强的鲁棒性 |
| RMAC,DINO | 基于深度的图像特征编码 | 对于图像篡改具有较强的鲁棒性 |
| 图文预训练模型 | 深度多模态 | 指标依赖于数据量 |
| 图音预训练模型 | 深度多模态 | 待补充 |
从第二步来看,将上述视频内容进行帧级特征表示,需要分析视频对之间一个或多个复制片段的相似性,并确定时间范围
经典时空建模方法如下
- Temporal Hough Voting
- graph-based Temporal Network
- temporal matching kernel
- LAMV
Reference
- https://richzhang.github.io/PerceptualSimilarity/index_files/poster_cvpr.pdf
- Poullot S , Tsukatani S , Nguyen A P , et al. Temporal Matching Kernel with Explicit Feature Maps[C]// Acm International Conference on Multimedia. ACM, 2015.
- L. Baraldi, M. Douze, R. Cucchiara, and H. Jegou. Lamv :Learning to align and match videos with kernelized temporal layers. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7804–7813, 2018. 1, 2, 3**
- M. Douze, H. Jegou, and C. Schmid. An image-based approach to video copy detection with spatio-temporal postfiltering. IEEE Transactions on Multimedia, 12(4):257–266,2010. 3, 7
- Hung-Khoon Tan, Chong-Wah Ngo, Richard Hong, and TatSeng Chua. Scalable detection of partial near-duplicate videos by visual-temporal consistency. MM ’09, page 145–154, New York, NY, USA, 2009. Association for Computing Machinery. 3, 7
本文使用 Zhihu On VSCode 创作并发布

